AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
"Native Quad-Core"
AMD has told the whole world and their pets that Barcelona is the first true quad-core as opposed to Intel's quad-cores which are twin dual cores. This should result in much better scaling, partly a result of the fact that cores should be able to exchange cache information much quicker.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2cache before; you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
AMD's native quad-core needs about 76ns to exchange (L1) cache information. That's not bad, but it's not fantastic either as the shared L2 cache approach of the Xeons allows the dual cores to exchange information via the L2 in about 26-30ns. Once you need to get information from core 0 to core 3, the dual die CPU of Intel still doesn't need much more time (77ns) than the quad-core Opteron (76ns). The complex L1-L2-L3 hierarchy might negate the advantages of being a "native" quad-core somewhat, but we have to study this a bit further as it is quite a complex matter.
Memory Subsystem
AMD has improved the memory subsystem of the newest Opteron significantly: the L1 cache is about the only thing that has not been changed: it's still the same 2-way set associative 64KB L1 cache as in K8, and it can be accessed in three cycles. Like every modern CPU, the new Opteron 2350 is capable of transferring about 16 bytes each cycle.
L2 bandwidth has been a weakness in the AMD architectures for ages. Back in the "K7 Thunderbird" days, AMD simply "bolted" the L2 cache onto the core. The result was a relatively narrow 64-bit path from the L2 cache to the L1 cache which could at best deliver about 2.4 to 3 bytes per cycle. The K8 architecture improved this number by 50% and more, but that still wasn't even close to what Intel's L2 caches could deliver per cycle. In the Barcelona architecture, The data paths into the L1 cache have been doubled once again to 256-bits. And it shows:
Barcelona, aka Opteron 23xx, is capable of delivering no less than 50%-60% more bandwidth to its L1 cache than K8. We also measure a latency of 15 cycles, which puts the AMD L2 cache in the same league as the Intel Core caches.
The memory controllers of the third generation of Opterons have also been vastly improved: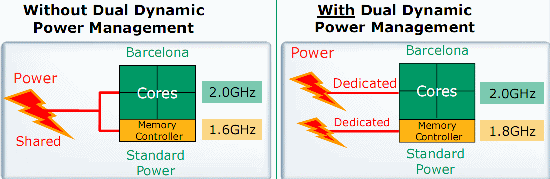
Okay, let's see if we can make all those promises of better memory performance materialize. We first tested with Lavalys Everest 4.0.11.
The deeper buffers and more flexible 2x64-bit accesses have increased the read bandwidth, but the write buffer might have negated the effect of those a bit. That is not a problem, as very few applications will be solely writing for a long period of time. Notice that per cycle, the improved copy bandwidth is 54% and is the biggest gain. This is most likely the result of the copy action resulting in an interleaving of writes and reads, allowing the split memory access design to come into play.
With much higher L2 cache and memory bandwidth combined with low latency access, the memory subsystem of the 3rd generation of Opterons is probably the best you can find on the market. Now let's try to find out if this superior memory subsystem offers some real world benefits.
AMD has told the whole world and their pets that Barcelona is the first true quad-core as opposed to Intel's quad-cores which are twin dual cores. This should result in much better scaling, partly a result of the fact that cores should be able to exchange cache information much quicker.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2cache before; you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
| Cache coherency ping-pong (ns) | |||
| Same die, same package | Different die, same package | Different die, different socket | |
| Opteron 2350 | 152 | N/A | 199 |
| Xeon E5345 | 59 | 154 | 225 |
| Xeon DP 5160 | 53 | - | 237 |
| Xeon DP 5060 | 201 | N/A | 265 |
| Xeon 7130 | 111 | N/A | 348 |
| Opteron 880 | 134 | N/A | 169-188 |
AMD's native quad-core needs about 76ns to exchange (L1) cache information. That's not bad, but it's not fantastic either as the shared L2 cache approach of the Xeons allows the dual cores to exchange information via the L2 in about 26-30ns. Once you need to get information from core 0 to core 3, the dual die CPU of Intel still doesn't need much more time (77ns) than the quad-core Opteron (76ns). The complex L1-L2-L3 hierarchy might negate the advantages of being a "native" quad-core somewhat, but we have to study this a bit further as it is quite a complex matter.
Memory Subsystem
AMD has improved the memory subsystem of the newest Opteron significantly: the L1 cache is about the only thing that has not been changed: it's still the same 2-way set associative 64KB L1 cache as in K8, and it can be accessed in three cycles. Like every modern CPU, the new Opteron 2350 is capable of transferring about 16 bytes each cycle.
| Lavalys Everest L1 Bandwidth | |||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Latency (ns) | |
| Opteron 2350 2 GHz | 32117 | 16082 | 23935 | 16.06 | 1.5 |
| Xeon 5160 3.0 | 47860 | 47746 | 95475 | 15.95 | 1 |
| Xeon E5345 2.33 | 37226 | 37134 | 74268 | 15.96 | 1.3 |
| Opteron 2224 SE | 51127 | 25601 | 44080 | 15.98 | 0.9 |
| Opteron 8218HE 2.6 GHz | 41541 | 20801 | 35815 | 15.98 | 1.1 |
L2 bandwidth has been a weakness in the AMD architectures for ages. Back in the "K7 Thunderbird" days, AMD simply "bolted" the L2 cache onto the core. The result was a relatively narrow 64-bit path from the L2 cache to the L1 cache which could at best deliver about 2.4 to 3 bytes per cycle. The K8 architecture improved this number by 50% and more, but that still wasn't even close to what Intel's L2 caches could deliver per cycle. In the Barcelona architecture, The data paths into the L1 cache have been doubled once again to 256-bits. And it shows:
| Lavalys Everest L2 Bandwidth | |||||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Opteron 2350 2 GHz | 14925 | 12170 | 13832 | 7.46 | 6.09 | 6.92 | 1.7 |
| Dual Xeon 5160 3.0 | 22019 | 17751 | 23628 | 7.34 | 5.92 | 7.88 | 5.7 |
| Xeon E5345 2.33 | 17610 | 14878 | 18291 | 7.55 | 6.38 | 7.84 | 6.4 |
| Opteron 2224 SE | 14636 | 12636 | 14630 | 4.57 | 3.95 | 4.57 | 3.8 |
| Opteron 8218HE 2.6 GHz | 11891 | 10266 | 11891 | 4.57 | 3.95 | 4.57 | 4.6 |
| Lavalys Everest L2 Comparisons | |||
| Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | |
| Barcelona versus Santa Rosa | 63% | 54% | 51% |
| Barcelona versus Core | -1% | -5% | -12% |
| Santa Rosa versus Core | -39% | -38% | -42% |
Barcelona, aka Opteron 23xx, is capable of delivering no less than 50%-60% more bandwidth to its L1 cache than K8. We also measure a latency of 15 cycles, which puts the AMD L2 cache in the same league as the Intel Core caches.
The memory controllers of the third generation of Opterons have also been vastly improved:
- Deeper buffers. The low latency integrated memory controller was already one of the strongest points of the Opteron, but the amount of bandwidth it could extract out of DDR2 was mediocre. Only at higher frequencies is the Opteron able to gain a bit of extra performance from fast DDR2-667 DIMMs (compared to DDR-400). This has been remedied in 3rd generation Opteron thanks to deeper request and response buffers.
- Write buffer. When Socket 939 and dual channel memory support was introduced, we found that the number of cycles that bus turnaround takes had a substantial impact on the performance of the Athlon 64. Indeed with a half duplex bus to the memory it takes some time to switch between writing and reading. When you fill up all the DIMM slots in a socket 939 system, the bus turnaround has to be set to two cycles instead of one. This results in up to a 9% performance hit, depending on how memory intensive your application is. So the way to get the best performance is to use one DIMM per channel and keep the bus turnaround at one cycle. However, even better than trying to keep bus turnaround as low as possible is to avoid bus turnarounds. A 16 entry write buffer in the memory controller allows Barcelona to group writes together and then burst the writes sequentially.
- More flexible. Each controller supports independent 64-bit accesses. (Dual core Opteron: a single 128-bit access across both controllers)
- DRAM prefetchers. The DRAM prefetcher works to request data from memory before it's needed when it sees that the memory is being accessed in regular patterns. It can go forward or backward in the memory.
- Better "open page" management. By keeping the right rows ready on the DRAM, the memory controller only has to pick out the right columns (CAS) to get the necessary data instead of searching for the right row, copying the row, and then picking out the right column. This saves a lot of latency (e.g. RAS to CAS), and can also save some power.
- Split power planes. Feeding the memory controller and the core from different power rails is not a direct improvement to the memory subsystem, but it does allow the memory controller to be clocked higher than the CPU core.
Okay, let's see if we can make all those promises of better memory performance materialize. We first tested with Lavalys Everest 4.0.11.
| Lavalys Everest Memory BW | |||||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Opteron 2350 2 GHz | 5895 | 4463 | 6614 | 2.95 | 2.23 | 3.31 | 76 |
| Dual Xeon 5160 3.0 | 3656 | 2771 | 3800 | 1.22 | 0.92 | 1.27 | 112.2 |
| Xeon E5345 2.33 | 3578 | 2793 | 3665 | 1.53 | 1.2 | 1.57 | 114.9 |
| Opteron 2224 SE | 7466 | 6980 | 6863 | 2.33 | 2.18 | 2.14 | 58.9 |
| Opteron 8218HE 2.6 GHz | 6944 | 6186 | 5895 | 2.67 | 2.38 | 2.27 | 64 |
| Lavalys Everest Memory BW Comparison | ||||
| Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Barcelona versus Santa Rosa | 26% | 2% | 54% | 29% |
| Barcelona versus Core | 92% | 86% | 111% | -34% |
| Santa Rosa versus Core | 74% | 99% | 44% | -44% |
The deeper buffers and more flexible 2x64-bit accesses have increased the read bandwidth, but the write buffer might have negated the effect of those a bit. That is not a problem, as very few applications will be solely writing for a long period of time. Notice that per cycle, the improved copy bandwidth is 54% and is the biggest gain. This is most likely the result of the copy action resulting in an interleaving of writes and reads, allowing the split memory access design to come into play.
With much higher L2 cache and memory bandwidth combined with low latency access, the memory subsystem of the 3rd generation of Opterons is probably the best you can find on the market. Now let's try to find out if this superior memory subsystem offers some real world benefits.








46 Comments
View All Comments
kalyanakrishna - Tuesday, September 11, 2007 - link
I don't deny people use MKL ... I dont agree that anyone targeting performance on AMD Opteron will use MKL. No one running HPL/Linpack for Top 500 submission would use MKL on Opteron. No one who wishes to test his Opteron for performance would use MKL to do so. No one wishing to have the fastest possible results from his Opteron will do so.Even ISV's now provide code that is optimized for Xeon and Opteron separately.
JohanAnandtech - Tuesday, September 11, 2007 - link
Ok, point taken. Give us some time, and we'll follow up with new compilations of Linpack.kalyanakrishna - Wednesday, September 12, 2007 - link
Thank you. Appreciate the effort.leexgx - Monday, September 10, 2007 - link
and how offen do you read anandtechs Previews and reviewsunlike when intels core 2 came out all the hipe was real, to bad for AMD this time
this cpu is going to be good, problem is will it be able to compleat with Intels new cpu when it comes out
i still useing an amd system if your wundering and so all the rest of my pcs apart from my server as i just thow in an old P4 mobo to just file sharein house (all second hand parts apart from the hdds)
phaxmohdem - Monday, September 10, 2007 - link
I wonder if it would be feasible for AMD to take the Intel approach, and slap two of there new native quad cores together and release an octal core CPU in the near future. Or would they remain the multi-core purists they have become... Similarly I wonder if 2 65nm Barecelona cores could even fit under that heat spreader... or come in under an acceptable thermal envelope.Accord99 - Monday, September 10, 2007 - link
It won't fit on Socket F:http://www.madboxpc.com/news/am2/AMD_barcelona.jpg">http://www.madboxpc.com/news/am2/AMD_barcelona.jpg
fic2 - Monday, September 10, 2007 - link
Page 8, 3DS Max 9 last paragraph:"Dual 3GHz Opteron 2222 is capable of generating about 29 frames per hour", but then
"potential 3GHz Barcelona will be able to spit out ~35 frames per second". I think that is supposed to be ~35 frames per hour. Otherwise that is an extremely impressive speedup!
JohanAnandtech - Monday, September 10, 2007 - link
No, it is "per second". We used a Octalcore 2THz Barcelona there.... Thanks, fixed that one :-)
phaxmohdem - Monday, September 10, 2007 - link
Got SuperPi times for that beast? ;)Roy2001 - Monday, September 10, 2007 - link
Kentsfield has 2*143mm^2 dies. Barcelona is 280+ mm^2. Penry would be even smaller, 2*100 mm^2. So unless AMD can increase the frequency to 3.0+Ghz soon and price their new quad-core processors higher than Intel's, AMD would be still in red unless it oursouces Athlon 64 to TSMC.