AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
64-bit Linux HPC Performance: LINPACK
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
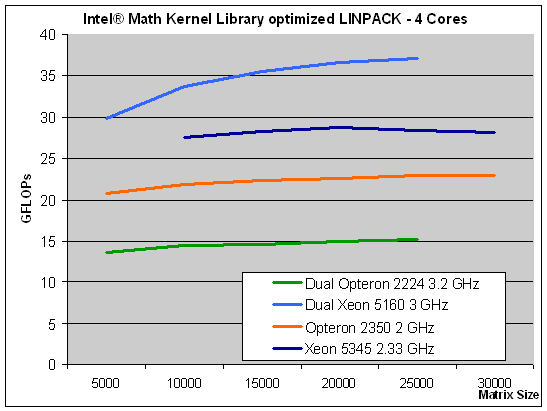
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
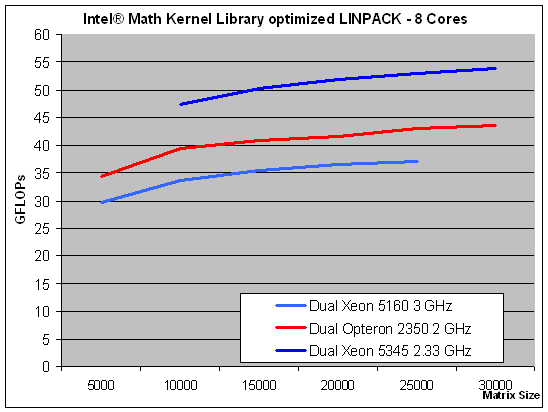
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
- Instruction fetch has been doubled to 32 bytes
- 128-bit SSE computations now decode into a single micro-op (two in K8)
- The load unit can load two 128-bit numbers from the L1 cache each cycle
- FP Reservation stations are still 36 entry, but they're now 128-bits wide instead of 64-bits
- All three FPU executions units were widened to 128-bit (64-bit before)
- The L2 cache has double the bandwidth to cope with this
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.








46 Comments
View All Comments
JohanAnandtech - Monday, September 10, 2007 - link
well said. I don't think AMD will have that advantage for a long time in 2P space :-)JackPack - Monday, September 10, 2007 - link
The problem is, 45nm Harpertown and 1600 MHz FSB will be rolling in soon.Barcelona would have looked great 6 or 9 months ago. But today, it's a little weak unless they can raise the frequency fast.
Viditor - Monday, September 10, 2007 - link
True, but so will HT 3.0 and the newer mem controller for the Barcelonas...
jones377 - Monday, September 10, 2007 - link
You got your work cut out for you now :)IntelUser2000 - Monday, September 10, 2007 - link
AMD won't compete against Intel's Tulsa chips anymore. They will have to compete against Tigerton Xeon MP and the newly introduced Clarksbro chipset.On the DP server platform, Intel will introduce Harpertown and Seaburg chipset. Seaburg chipset features 1600MHz bus with significantly improved memory controller performance. We'll see how it all turns out but as of now, Barcelona is a bit late to be competitive.
wegra - Monday, September 10, 2007 - link
You should not forget the Penryn. 2.5Ghz Barcelona will face to 3.1+Ghz Penryn. According to result from this article, I expect the performance of 2.5Ghz Barcelona will reach between 2.8 ~ 2.9Ghz Penryn. So wait till (hopefully) next year to see that AMD becomes the performance king. BTW, talking about the multi-processor servers, AMD will lead w/o much difficulties, I expect, thanks to the scalable architecture.