AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
64-bit Linux HPC Performance: LINPACK
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
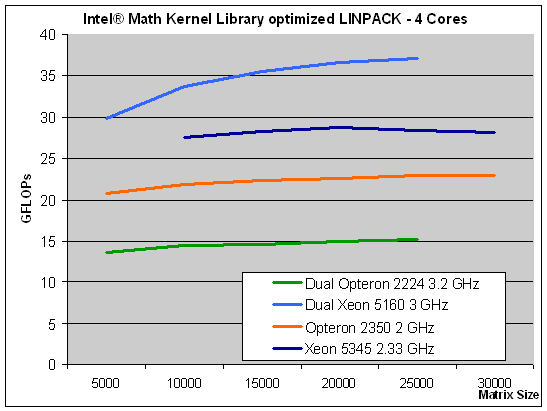
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
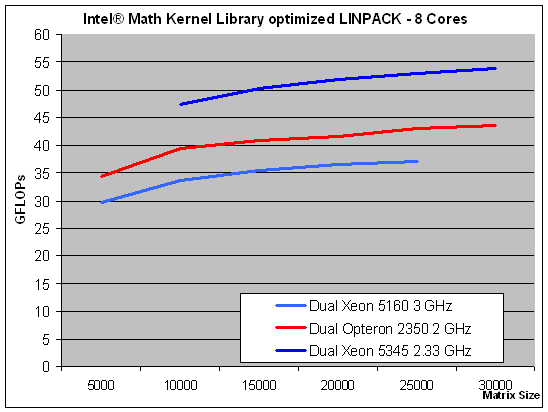
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
- Instruction fetch has been doubled to 32 bytes
- 128-bit SSE computations now decode into a single micro-op (two in K8)
- The load unit can load two 128-bit numbers from the L1 cache each cycle
- FP Reservation stations are still 36 entry, but they're now 128-bits wide instead of 64-bits
- All three FPU executions units were widened to 128-bit (64-bit before)
- The L2 cache has double the bandwidth to cope with this
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.








46 Comments
View All Comments
tshen83 - Monday, October 1, 2007 - link
according to mysql site, starting with 5.0.37, the mutex contention bug and the Innodb bug has been improved by a lot, which helps 8 core systems.I was wondering that since 5.0.45 is available on mysql's website, why isn't the latest mysql being benchmarked? 5.0.26 still has that bug, and you can see it in the benchmark where a 8 core system is slower than a 4 core which is slower than a 2 core.
Now that we are benchmarking 8-16 core systems, the newest versions of software should be used to reflect the improved multithreading.
swindelljd - Wednesday, September 12, 2007 - link
I currently have a 4 way 2.4ghz opteron as a production db server that I am considering upgrading. I'm trying to use the Anandtech benchmarks to help project how much performance gain we'll see in a new machine.We're running Oracle but are considering moving to MySQL. So I am trying to compare the stat's in 2 Anandtech reviews to see how the new Barcelona cores compare to the Intel Woodcrest and Clovertown.
In looking at this article from June 2006( http://www.anandtech.com/IT/showdoc.aspx?i=2772&am...">http://www.anandtech.com/IT/showdoc.aspx?i=2772&am... ) , 2x3ghz Woodcrests (4 cores, right?) run the MySQL test at about 950 QPS (queries per second) for 25,50 and 100 concurrent sessions.
However this recent article in September 2007 ( http://www.anandtech.com/IT/showdoc.aspx?i=3091&am...">http://www.anandtech.com/IT/showdoc.aspx?i=3091&am... ) appears to show the same 2x3ghz Woodcrests running 700,750 and 850 QPS for 25,50 and 100 connections respectively. That represents a 20% or so DECREASE in performance of the same chip in the last 12 months.
What am I missing?
Ultimately I want to compare the Opteron 2350 vs Xeon 5345 and then the Opteron 8350 vs Xeon E7330 but I'm starting with what exists for benchmarks first so I can make sure I understand what I am reading.
Can someone please help set me straight.
thanks,
John
JohanAnandtech - Monday, September 17, 2007 - link
The article in june 2006 uses 5.0.21, and there might also be a small change in tuning. The article in September 2007 uses the standaard 5.0.26 mysql version that you get with SLES 10 SP1.The best numbers are here:
http://www.anandtech.com/cpuchipsets/intel/showdoc...">http://www.anandtech.com/cpuchipsets/intel/showdoc...
The newest version 5.0.45 will give you performance like the above article: MySQL has incorporated the Patches we talked about (that Peter Z. wrote) in this new version.
Jjoshua2 - Tuesday, September 11, 2007 - link
I like this benchmark alot as I am a fan of computer chess. Higher was spelled wrong on the graph on that page in Hiher is better.Schugy - Tuesday, September 11, 2007 - link
Maybe it's too early for gcc optimizations but how about testing programs like oggenc, ffmpeg, blender, kernel compilation, apache with openssl, doom III and so on?erikejw - Monday, September 10, 2007 - link
I read another review and they got these scores on the slightly lowerspeed 1.9 GHz Barcelona.Barcelona 2347 (1.9Ghz)
37.5 Gflop/s
Intel Xeon 5150(2.6Ghz)
35.3 Gflop/s
It seems your Barcelona scores are way off for some reason.
The Xeons score is more or less identical.
This seems really weird. Normally the higher score is the correct one due to some bad optimizations. The rest of the article is great though.
kalyanakrishna - Monday, September 10, 2007 - link
This article seems to be very biased.1) they choose faster Intel processors, 2 GHz Opteron. There are 2 GHz processors available across all the processors used in this analysis.
2) No mention of what compiler was used. Intel compilers earlier had a trick, which was not documented - any code optimized for Intel processors if used on non-intel processors (uhm! AMD), would disable all optimizations. Who knows what else they are doing now. And this gentleman used Intel optimized code on AMD to test performance. Who in the right mind measuring performance would do that?
3) Intel MKL was used for BLAS. Shouldnt they use ACML for AMD code? Again, who would do that when looking for performance?
4) Memory Subsystem - knowing that the frequencies are different, why were all the results not normalized?
5) They managed to comment that Tulsa and Opteron 2000 series are half the performance of core or Barcelona and hence should not be considered in the first page. But in Linpack page, it is mentioned that Intel chips ate AMD ones for breakfast. Of course, they did - peak of Xeon 5100 series is twice that of Opteron 2000 series. You dont need LINPACK to tell you that. Gives a very biased impression.
6) LinPACK results graph could not be any more wrong. The peak performance of each CPU considered is different ... obviously their sustained performance is going to be different. The author should have at least made the effort to normalize the graph to show the real comparison.
7) Since when is Linpack "Intel friendly"
The author says they didnt have time to optimize code for AMD Opteron ... why would you do a performance study in the first place if you didnt have the methodology right.
I didnt even read beyind LinPACK .. I would be careful reading articles from this author next time and maybe the whole site ... Its sad to see such an immature article. Whats worse is majority of people would just see the "fact" Intel is still faster than AMD.
Over all, a very immature article with false information cleverly hidden behind numbers. or could it be that this article was intended to be biased .... who knows.
JohanAnandtech - Monday, September 10, 2007 - link
What about the bytes/Cycle in each table?
Why is that the "real comparison"? If Intel has a clockspeed advantage, nobody is going to downclock their CPUs to be fair to AMD.
First you claim we are biased. As we disclose that the binary that we run was compiled with Intel compilers targetting Core architecture, it is clear that the binary is somewhat Intel friendly.
It not wrong. It is incomplete and we admit that more than once. But considering AMD gaves us a few days before the NDA was over, it was impossible to cover all angles.
erikejw - Tuesday, September 11, 2007 - link
That is true in the desktop scene but I am sure you know that servers is about performance/price and performance/w. Prices will declinge and we don't know what the price is tomorrow. It is ok to compare against a similarly priced cpu but a comparison against a
same frequency cpu is very interesting too.
Your LINPACK score just seems obscure. Somewhat Intel friendly compiler? LOL. If the compiler is so great why is the gcc score I read on another review 30% higher with the Barcelona(with a 1.9 GHz CPU)? That is just ridiculous. I thought this review was about architechture and what it can perform and not about which compiler we use and if it is true that optimizations is turned off in then Intel compiler if it is an AMD cpu then the score is worthless and the comparison is severly biased.
JohanAnandtech - Tuesday, September 11, 2007 - link
Which review? Did they fully disclose the compiler settings?
If the Intel compiler did fool us and turned off optimisations, we will update the numbers.