HyperZ: Attacking the Memory Bandwidth Issue
At 166MHz, the Radeon SDR’s core features a 1 Gigatexel/s fill rate, however because of its limited memory bandwidth, the Radeon SDR will never see a real world fill rate that high. This is the same situation that was present with the GeForce2 MX that would never take advantage of its 700 Megatexels/s fill rate because of similar memory bandwidth limitations.
ATI does have a trick up their sleeve however that could theoretically help the Radeon SDR not fall victim to the same fate as the memory bandwidth crippled GeForce2 MX. This trump card is ATI’s HyperZ technology. Primarily achieving a decrease in memory bandwidth utilization by efficiently caching and compressing data stored in the Z-buffer (data pertaining to depth), HyperZ can, according to ATI, increase available memory bandwidth up to 20%.
With the Radeon SDR suffering from an available 2.7GB/s memory bandwidth, eqvuivalent to that of a GeForce SDR or a GeForce2 MX, the Radeon SDR needs all the help it can get to more efficiently manage its limited memory bandwidth.
The HyperZ technology is essentially composed of three features that work in conjunction with one another to provide for this "increase" in memory bandwidth. In reality, the increase is simply a more efficient use of the memory bandwidth that is there. The three features are: Hierarchical Z, Z-Compression and Fast Z-Clear. Before we explain these features and how they impact performance, you have to first understand the basics of conventional 3D rendering.
As we briefly mentioned before, the Z-buffer is a portion of memory dedicated to holding the z-values of rendered pixels. These z-values dictate what pixels and eventually what polygons appear in front of one another when displayed on your screen, or if you're thinking about it in a mathematical sense, the z-values indicate position along the z-axis.
A traditional 3D accelerator processes each polygon as it is sent to the hardware, without any knowledge of the rest of the scene. Since there is no knowledge of the rest of the scene, every forward facing polygon must be shaded and textured. The z-buffer, as we just finished explaining, is used to store the depth of each pixel in the current back buffer. Each pixel of each polygon rendered must be checked against the z-buffer to determine if it is closer to the viewer than the pixel currently stored in the back buffer.
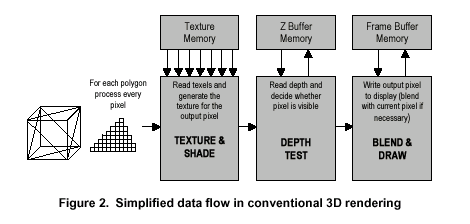
Checking against the z-buffer must be performed after the pixel is already shaded and textured. If a pixel turns out to be in front of the current pixel, the new pixel replaces (or is blended with in the case of transparency) the current pixel in the back buffer and the z-buffer depth updated. If the new pixel ends up behind the current pixel, the new pixel is thrown out and no changes are made to the back buffer (or blended in the case of transparency). When pixels are drawn for no reason, this is known as overdraw. Drawing the same pixel three times is equivalent to an overdraw of 3, which in some cases is typical.
Once the scene is complete, the back buffer is flipped to the front buffer for display on the montior.
What we've just described is known as "immediate mode rendering" and has been used since the 1960's for still frame CAD rendering, architectural engineering, film special effects, and now in most 3D accelerators found inside your PC. Unfortunately, this method of rendering results in quite a bit of overdraw, where objects that aren't visible are being rendered.
One method of attacking this problem is to implement a Tile Based Rendering architecture, such as what we saw with the PowerVR Series 3 based KYRO graphics accelerator from ST Micro. While that may be the ideal way of handling it, developing such an algorithm requires quite a bit of work, it took years for Imagination Technologies (the creator of the PowerVR chips) to get to the point they are today with their Tile Based Rendering architecture.
For this time around, that wasn't a possibility for ATI, as they needed to get the Radeon on the market as soon as possible to avoid otherwise devestating consequences of losing market share. Instead, ATI's solution was to optimize the accesses to the Z-buffer. From the above example of how conventional 3D rendering works, you can guess that quite a bit of memory bandwidth is spent on accesses to the Z-buffer in order to check to see if any pixels are in front of the one being currently rendered. ATI's HyperZ increases the efficiency of these accesses, so instead of attacking the root of the problem (overdraw), ATI went after the results of it (frequent Z-buffer accesses).








0 Comments
View All Comments